
티스토리 뷰
1. Data Acquirement
1.1.1 데이터 불러오기
keyword: read_csv, crosstab
#read_csv 함수 사용하여 데이터 불러오기
flight = pd.read_csv('./Clean_Dataset.csv', encoding = "cp949")# read_csv 함수의 파라미터를 활용하여 원하는 칼럼만 가지고 데이터 프레임 만들기
flight2 = pd.read_csv('./Clean_Dataset.csv', index_col='stops',
usecols=['stops', 'departure_time','arrival_time','destination_city'])
# crosstab확인하기
pd.crosstab(index=flight.source_city, columns=flight.arrival_time) #교차표 형태로 빈도
2. 데이터 구조
2.1.1 데이터 확인하기
keyword: head, tail, shape, columns, info, describe, dtypes, value_counts
flight.head(n=10)flight.tail()flight.shapeflight.columns# Number of x entries(rows), Columns, Non-Null Count, Dtypes
flight.info()# Summary statistics
flight.describe()# dtypes 확인하기
flight.dtypes# value_counts 확인하기
flight['source_city'].value_counts()
3. 기초 데이터 다루기
keyword: 부분데이터, 데이터 변경, 데이터프레임 변형, 데이터프레임 병합
- 부분데이터: 슬라이싱, index, loc, iloc, condition
- 데이터 변경: 연산으로 컬럼추가, insert, drop, rename, sort_values
- 데이터프레임 변형: groupby, set_index, pivot, pivot_table, unstack, stack
- 데이터프레임 병합: concat, merge
3.1 부분데이터
3.1.1 부분데이터 Extract (using index, column)
# 하나의 칼럼만 선택하기
flight[['departure_time']]
# 하나의 칼럼 선택 but in series
flight['departure_time']# 여러 개의 칼럼 선택하기
flight[['airline','departure_time','source_city']]# 슬라이싱을 이용하여 10행부터 20행까지의 데이터를 가져오기
flight[10:21]# 인덱스 새롭게 지정하기
flight.index = np.arange(100,300253)
flight
# loc 사용하기
flight.loc[[102, 202, 302]]
# iloc 사용하기
flight.iloc[[2, 102, 202]]
# loc를 사용하여 행과 열의 범위 지정하기
flight.loc[[102, 202, 302], ['airline', 'flight', 'source_city', 'price']]
# iloc를 사용하여 행과 열의 범위 지정하기
flight.iloc[[2, 102, 202], [1, 2, 3, 11]]
3.1.2 부분데이터 Extract (condition)
# boolean 연산으로 조건을 만족하는 데이터만 추출하기
flight_extract = flight[(flight['price']>12000) & (flight['airline']=='Air_India')]
3.2 데이터 변경
3.2.1 데이터 추가
# 새로운 칼럼 만들기
flight['price2'] = flight['price'] * 2
# 기존 칼럼 연산으로 새로운 칼럼 만들기
flight['price3'] = flight['price'] + flight['price2']
# 새로운 칼럼 원하는 위치에 넣기
flight.insert(10, 'duration2', flight['duration'] *10)
#parameter at #3 is a formula to compute the newly made column
3.2.2 데이터 삭제
# drop 메소드 사용하여 데이터 삭제 하기
flight.drop('price3', axis=1).head()
# axis 속성 이해하기
flight.drop(index=0, axis=0).head()
# 데이터 삭제 후 새로운 데이터프레임에 저장하기
flight1=flight.drop('price3', axis=1)
# 데이터 삭제 후 commit하기
flight.drop('price3', axis=1, inplace=True)
3.2.3 칼럼명 변경
# rename 이용하여 칼럼명 변경하기
flight=flight.rename(columns = {"airline" : 'airline_name',"source_city":'departure_city'})
3.2.4 데이터 프레임 정렬
# sort_values 메소드와 ascending 매개변수 지정하여 데이터 프레임 역순으로 정렬하기
flight=flight.sort_values(by ='Unnamed: 0', ascending=False) # ascending=True
3.3 데이터프레임 변형
3.3.1 그룹화
groupby로 그룹화
# airline 칼럼 기준으로 그룹화하기
airline_group = flight.groupby('airline')
# output: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002150259BE50>
# 데이터 수 확인하기
airline_group.count()
# 최솟값 확인하기
airline_group.min()
# 평균값 확인하기
airline_group.mean()
# 특정 칼럼 값만 확인하기
airline_group.mean()[['price']]
# groupby를 활용하여 다중 인덱싱(multi-indexing)설정하기
flight.groupby(['airline', 'arrival_time']).mean()
# 여러 개의 칼럼을 groupby하여 새로운 데이터프레임 생성하기
mul_airline_group=flight.groupby(['airline', 'arrival_time'])
# groupby 후 원하는 데이터만 가지고 오기
flight.groupby(['airline', 'arrival_time']).mean().loc[[('AirAsia','Evening')]]
인덱스 그룹화
# set_index로 인덱스 지정하기 (다중 인덱스)
flight.set_index(['airline','arrival_time'])
# 다중 인덱스(multi-index) 셋팅 후 해당 인덱스 기준으로 groupby하기
flight.set_index(['airline','arrival_time']).groupby(level=[0]).mean()
# 결과값: 결국 arrival time 컬럼은 사라지고 airline으로 groupby된셈
# 인덱스 모두 선택하여 groupby 하기
flight.set_index(['airline','arrival_time']).groupby(level=[0,1]).mean()
# flight.groupby(['airline', 'arrival_time']).mean()와 동일한 결과값
Aggregate으로 여러 statistics 집계
# aggregate 메소드 이용하여 groupby 후 평균값과 최댓값 확인하기
flight.set_index(['airline','arrival_time']).groupby(level=[0,1]).aggregate([np.mean, np.max])
3.3.2 피벗테이블 생성
# pivot 활용하기
pivot_data.pivot(index = 'cust_id', columns ='prod_cd', values ='purch_amt')
# 해당 pivot data는 아래와 같이 코드를 작성할 수도 있습니다.
# pivot_data('cust_id', 'prod_cd', 'pch_amt')
# 중복값이 존재하는 경우 에러 메시지# pivot_table 활용하기
pivot_data.pivot_table(index='grade', columns='prod_cd', values='purch_amt')
# pivot_table의 aggfunc 지정하기
pivot_data.pivot_table(index='grade', columns='prod_cd', values='purch_amt', aggfunc=np.sum)
"""pivot: 단순한 피벗 테이블을 생성하며, 단일 값 열만 사용 가능합니다.
pivot_table: 여러 값 열을 사용할 수 있고, 집계 함수를 지정할 수 있으며,
다중 인덱스, 결측값, 중복값 처리를 지원합니다."""3.3.3 인덱스 및 칼럼 레벨 변경
# 인덱스 설정하기
new_stack_data = stack_data.set_index(['Location','Day'])
new_stack_data.unstack(0) #0번째 인덱스(Location) unstack => 컬럼으로 stack
new_stack_data.unstack(1) #1번째 인덱스(Location) unstack => 컬럼으로 stack
new_stack_data2.stack(1) #1번째 컬럼stack unstack => 인덱스로 stack
3.4 데이터프레임 병합
3.4.1 concat으로 병합
# ignore_index 확인하기
pd.concat([df1, df2], ignore_index=False)
# concat axis 이해하기
pd.concat([df1, df2], axis = 1)
# join의 outer 방식
pd.concat([df3, df4], join='outer')
# join의 inner 방식
pd.concat([df3, df4], join='inner')
concat : 주로 데이터프레임을 단순하게 이어 붙이는 데 사용
merge: 데이터베이스의 조인과 유사하게 특정 키를 기준으로 데이터프레임을 결합
3.4.2 merge/join으로 병합
# merge 함수의 on 속성 이해하기
pd.merge(customer, orders, on='customer_id')
# merge 함수의 how 속성 이해하기
pd.merge(customer, orders, on='customer_id', how='inner')
pd.merge(customer, orders, on='customer_id', how='left')
pd.merge(customer, orders, on='customer_id', how='right')
pd.merge(customer, orders, on='customer_id', how='outer')
# 인덱스를 지정하여 데이터프레임 합치기
cust1=customer.set_index('customer_id')
order1=orders.set_index('customer_id')
pd.merge(cust1, order1, left_index=True, right_index=True)
# 가장 많이 팔린 아이템 구하기 (아이템별 합 구하고 정렬)
pd.merge(customer, orders, on='customer_id', how='right').groupby('item').sum().sort_values(by='quantity', ascending=False)
# Elly가 가장 많이 구매한 물건
pd.merge(customer, orders, on='customer_id', how='inner').groupby(['name','item']).sum().loc['Elly']
4. 데이터 이해하기
keyword: 지표로 데이터 탐색(일변량, 다변량), 시각화로 데이터 탐색(일변량, 다변량, Seaborn)
- 지표
- 일변량: describe, value_counts
- 다변량: corr
- 시각화
- 일변량: 선 그래프, 막대 그래프, 파이 그래프, 도수분포표(histogram), 상자 그래프
- 다변량: 산점도(scatter plot), 히트맵
- Seaborn: 범주형 산점도(categorical plot), 선형회귀 모델 그래프(linear model plot), 빈도 그래프(count plot), 조인트 그래프, 히트
4.1 지표로 데이터 탐색
4.1.1 일변량 비시각화 탐색
# 전체 칼럼의 요약통계량 확인하기
df.describe(include='all')
# airline, source_city, destination_city의 빈도표 확인하기
print(df["airline"].value_counts())
print(df["source_city"].value_counts())
print(df["destination_city"].value_counts())
4.1.2 다변량 비시각화 탐색
# 데이터의 상관계수 확인하기
df.corr()
# class를 Economy로 한정하여 새로운 데이터프레임 df_eco 생성하기
df_eco=df[(df['class']=='Economy')]
# df_eco의 상관계수 확인하기
df_eco.corr()
# source_city와 departure_time 두 범주형 변수의 변수간의 관계 확인하기
pd.crosstab(df['source_city'], df['departure_time'])
4.2 시각화로 데이터 탐색
4.2.1 일변량 시각화 탐색
# Line Plot
# days_left별 평균 데이터 만들기
days_left=df.groupby('days_left').mean()
days_left.head()
# 시각화 라이브러리 불러오기
import matplotlib.pyplot as plt
# 시각화 영역(figure) 지정하기
plt.figure()
# days_left의 price 데이터로 선 그래프 그리기
plt.plot(days_left['price'])
# X축 이름 지정하기
plt.xlabel("Days_left")
# Y축 이름 지정하기
plt.ylabel("Price")
# 시각화 표기하기
plt.show()
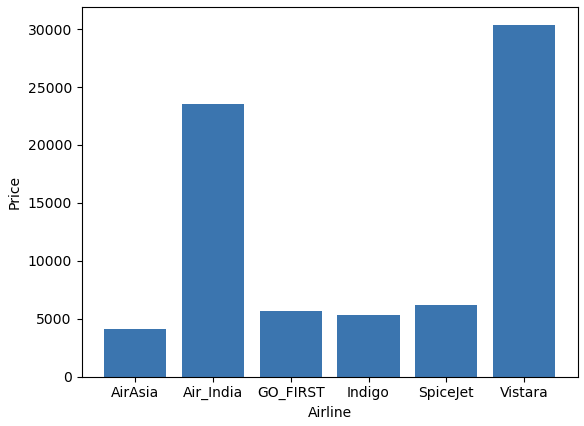
# Bar plot
# airline별 평균 데이터 만들기
airline=df.groupby(['airline']).mean()
airline
# 인덱스를 리스트로 만들기
label = airline.index
plt.figure()
# 인덱스를 X, 평균가격을 Y로 하는 막대 그래프 그리기
plt.bar(label, airline['price'])
plt.xlabel("Airline")
plt.ylabel("Price")
plt.show()
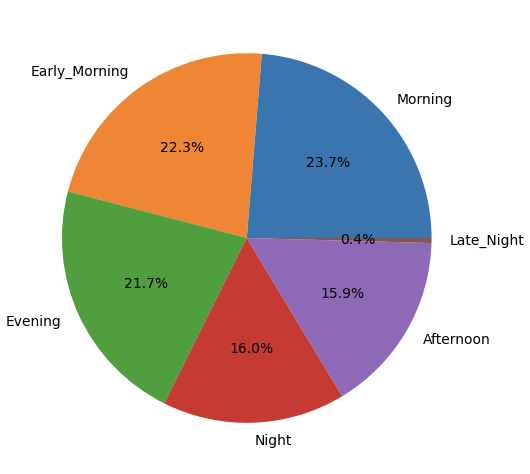
# Pie Graph
# departure_time 빈도표 데이터 만들기
departure_time=df['departure_time'].value_counts()
plt.figure(figsize=(10,6))
# departure_time 빈도표 데이터로 파이 그래프 그리기
plt.pie(departure_time, labels=departure_time.index, autopct='%.1f%%')
plt.show()
# histogram
plt.figure()
# duration을 20개 구간으로 나눠서 히스토그램 그리기
plt.hist(df['duration'], bins=10)
# duration을 10개 구간으로 나눠서 히스토그램 그리기
plt.hist(df['duration'], bins=20)
plt.xlabel("Duration")
plt.ylabel("Flights")
# 동시에 2개의 그래프를 하나의 시각화 영역에 그려 범례 지정하기
plt.legend(("Bin 10", "Bin 20"))
plt.show()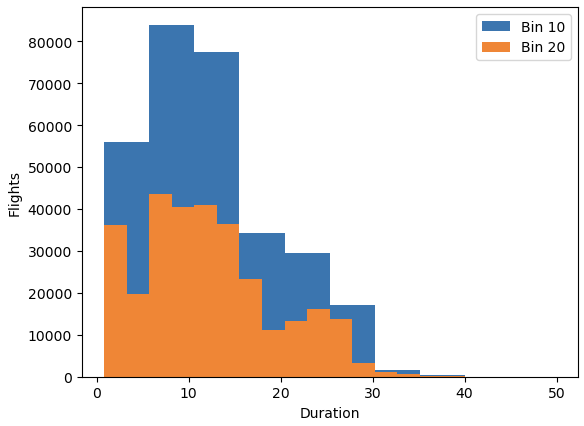
# box plot
plt.figure()
# Price 칼럼에 대한 상자 그래프 그리기
plt.boxplot(list(df['price']))
plt.ylabel("price")
plt.show()
# departure_time별로 price에 대한 상자 그래프 그리기
df.boxplot(by="departure_time", column="price", figsize=(10,8))
4.2.2 다변량 시각화 탐색
# Scatter Plot
plt.figure(figsize=(16,8))
# price와 dration간의 산점도 그리기
plt.scatter(y=df["price"], x=df["duration"])
plt.xlabel("Duration")
plt.ylabel("Price")
plt.show()
# Heatmap
# numpy 불러오기
import numpy as np
# 상관계수 데이터 만들기
heat=df_eco.corr()
# 상관계수로 heatmap그리기
plt.pcolor(heat)
# x축 항목 정보 표기하기
plt.xticks(np.arange(0.5, len(heat.columns), 1), heat.columns)
# y축 항목 정보 표기하기
plt.yticks(np.arange(0.5, len(heat.index), 1), heat.index)
# 히트맵 확인을 위한 컬러바 표기하기
plt.colorbar()
plt.show()
4.2.3 Seaborn 시각화
# Categorical Plot
# seaborn 불러오기
import seaborn as sns
# airline별 price를 class로 구분하여 시각화 하기
sns.catplot(y="airline", x="price", col='class', data=df)
# Linear Model Plot
# duration과 price의 회귀선을 빨간색으로 표시해서 시각화 하기
sns.lmplot(x='duration', y='price', data=df_eco, line_kws={'color': 'red'})
# Count Plot
# 항공권 데이터의 빈도를 airline으로 구분하여 class별로 시각화 하기
sns.countplot(x="airline", hue="class", data=df)
# Joint Graph
# price와 duration간의 관계를 joint plot으로 시각화 하기
sns.jointplot(y="price", x="duration", data=df_eco)
# heatmap
# 상관계수로 heatmap그리기
sns.heatmap(df_eco.corr())
5. 데이터 전처리하기
keyword: 수치형 데이터 정제, 범주형 데이터 정제, 스케일링, 변수 선택
- 수치형 데이터 정제
- 결측치 파악: info, isnull
- 결측치 처리: dropna, fillna
- 이상치 파악: z-score, IQR(Inter-Quartile Range)
- 이상치 처리: 이상치 데이터 삭제, 이상치 데이터 대체
- 구간화: cut, qcut
- 범주형 데이터 정제
- 레이블 인코딩: factorize # 판다스, LabelEncoder #사이킷런
- 원핫 인코딩: get_dummies #판다스, OneHotEncoder #사이킷런
- 스케일링: 정규화, 표준화
- 변수선택: 하나의 데이터로 여러 개의 새로운 컬럼 만들기, 여러 개의 데이터로 하나의 새로운 컬럼 만들기 # apply(lambda x : ...)
5.1 수치형 데이터 정제하기
5.1.1 결측치 파악하기
1. 결측치 존재 여부 확인하기
# 데이터 정보 확인하기
# info로 결측치 존재 확인 가능
df_na.info()
2. 결측치 수 확인하기
# 결측치 수 확인하기
df_na.isnull().sum(axis=0)
5.1.2 결측치 처리하기
# 데이터 변경에 대비하여 원본 데이터 복사하기
df_na_origin=df_na.copy()
1. 결측치 삭제하기
# 결측치를 하나라도 가지는 행 모두 삭제하기
df_na=df_na.dropna()
# 모든 데이터가 결측치인 행만 삭제하기
df_na=df_na.dropna(how='all')
2. 칼럼 제거하기
# stops과 flight 제거하기
df_na=df_na.drop(['stops','flight'], axis=1)
3. 결측치 대체하기
# 칼럼별 평균값으로 결측치 대체하기
df_na=df_na.fillna(df_na.mean())
# bfill을 이용한 결측치 대체하기 (결측값을 다음 유효한 값으로 채움)
df_na=df_na.fillna(method='bfill')
5.1.3 이상치 파악하기
1. z-score로 확인하기
# Z-score를 기준으로 신뢰 수준이 95%인 데이터 확인하기
df[(abs((df['price']-df['price'].mean())/df['price'].std()))>1.96]
2. IQR(Inter-Quartile Range)로 확인하기
# IQR 기준 이상치 확인하는 함수 만들기
def findOutliers(x, column):
# 제1사분위수 q1 구하기
q1 = x[column].quantile(0.25)
# 제3사분위수 q3 구하기
q3 = x[column].quantile(0.75)
# IQR의 1.5배수 IQR 구하기
iqr = 1.5 * (q3 - q1)
# 제3사분위수에서 IQR의 1.5배보다 크거나 제1사분위수에서 IQR의 1.5배보다 작은값만 저장한 데이터 y 만들기
y=x[(x[column] > (q3 + iqr)) | (x[column] < (q1 - iqr))]
# IQR기준 이상치 y 반환하기
return len(y)
# price, duration, days_left 에 대하여 IQR기준 이상치 개수 확인하기
print("price IQR Outliers : ",findOutliers(df,'price'))
print("durationIQR Outliers : ",findOutliers(df,'duration'))
print("days_left IQR Outliers : ",findOutliers(df,'days_left'))# 시각화를 위해 matplotlib.pyplot 불러오기
import matplotlib.pyplot as plt
plt.figure()
# 첫 번째 subplot : 1행 5열로 나눈영역에서 첫번째 영역
plt.subplot(151)
df[['duration']].boxplot()
plt.ylabel("Time")
# 두 번째 subplot : 1행 5열로 나눈영역에서 세번째 영역
plt.subplot(153)
df[['days_left']].boxplot()
plt.ylabel("Days")
# 세 번째 subplot : 1행 5열로 나눈영역에서 다섯번째 영역
plt.subplot(155)
df[['price']].boxplot()
plt.ylabel("Price")
plt.show()
5.1.4 이상치 처리하기
1. 이상치 데이터 삭제하기
# 신뢰도 95% 기준 이상치 Index 추출하기
outlier=df[(abs((df['price']-df['price'].mean())/df['price'].std()))>1.96].index
# 추출한 인덱스의 행 삭제해서 clean_df 데이터 만들기
clean_df=df.drop(outlier)
clean_df.info()
plt.figure(figsize=(4,5))
# 박스 그래프 활용하여 이상치 제거 여부 확인하기
clean_df[['price']].boxplot()
plt.show()
2. 이상치 데이터 대체하기
# IQR 기준 이상치를 대체하는 함수 만들기
def changeOutliers(x, column):
# 제1사분위수 q1 구하기
q1 = x[column].quantile(0.25)
# 제3사분위수 q3 구하기
q3 = x[column].quantile(0.75)
# IQR의 1.5배수 IQR 구하기
iqr = 1.5 * (q3 - q1)
# 이상치를 대체할 Min, Max값 설정하기
Min=(q1 - iqr)
Max = q3 + iqr
# Max보다 크값은 Max로, Min보다 작은값은 Min으로 대체하기
x.loc[(x[column] > Max), column]= Max
x.loc[(x[column] < Min), column]= Min
# x리턴하기
return(x)
# price에 대하여 이상치 대체하기
clean_df=changeOutliers(df, 'price')
clean_df.info()# price에 대하여 IQR기준 이상치 개수 확인하기
print("price IQR Outliers : ",findOutliers(clean_df,'price'))
plt.figure(figsize=(4,5))
# 박스그래프 활용하여 이상치 대체 여부 확인하기
clean_df[['price']].boxplot()
plt.show()
5.1.5 구간화(binning)하기
1. 동일 길이로 구간화하기
# 비행시간을 0~5, 5~10, 10 이상의 3개의 구간으로 나누어 거리(distance)) 칼럼 생성하기
df['distance']=pd.cut(df['duration'],
bins=[0,5,10,df['duration'].max()], labels=['short','medium' ,'long'])
# 거리 칼럼의 빈도분포 확인하기
df['distance'].value_counts()
2. 동일 개수로 구간화하기
# 항공권 가격(price)를 4개 구간으로 동일하게 나누어 항공권 가격 비율 칼럼 생성하기
df['price_rate']=pd.qcut(df['price'], 4,
labels=['cheap','nomal' ,'expensive', 'too expensive'])
# 항공권 가격 비율 칼럼의 빈도 분포 확인하기
df['price_rate'].value_counts()
5.2 범주형 데이터 정제하기
5.2.1 레이블 인코딩 하기
1. Pandas로 레이블 인코딩 하기
# factorize로 airline 칼럼 레이블 인코딩하기
df["label_encoding"] = pd.factorize(df["airline"])[0].reshape(-1,1)
This extracts the first object from the tuple returned by pd.factorize,
which is the array of encoded labels. => The reshape(-1, 1) function reshapes
the 1D array of encoded labels into a 2D array with a single column.
Here, -1 means the number of rows is inferred automatically based on the length of the array.

2. Scikit-learn으로 레이블 인코딩 하기
# 사이킷런 패키지의 LabelEncoder 불러오기
from sklearn.preprocessing import LabelEncoder
# LabelEncoder로 airline 칼럼 레이블 인코딩하기
le = LabelEncoder()
df["airline_Label_Encoder"] = le.fit_transform(df['airline'])
# 레이블 인코딩 역변환(디코딩)하기
le.inverse_transform(df["airline_Label_Encoder"]).reshape(-1,1)
5.2.2 원핫 인코딩
- 레이블 인코딩: 각 범주를 고유한 정수로 변환합니다. 단순하지만 범주 간의 관계가 없는 경우 부적절할 수 있습니다.
- 원핫 인코딩: 각 범주를 이진 벡터로 변환합니다. 범주 간의 관계를 제거하지만 메모리 사용량이 증가할 수 있습니다.
1. Pandas로 원핫 인코딩
#레이블 인코딩 전 원본데이터 불러오기
df=df_origin.copy()
#class 칼럼을 원핫인코딩 하기
pd.get_dummies(df['class'])
# 원핫 인코딩 결과를 데이터에 반영하기
df=pd.get_dummies(df, columns=['class'])
df.head()
1. Scikit-learn으로 원핫 인코딩
#판다스 원핫인코딩 전 원본데이터 불러오기
df=df_origin.copy()
#사이킷런 패키지에서 OneHotEncoder 불러오기
from sklearn.preprocessing import OneHotEncoder
#OneHotEncoder로 원핫 인코딩 하기
oh = OneHotEncoder()
encoder = oh.fit_transform(df['class'].values.reshape(-1,1)).toarray()
#원핫인코딩 결과를 데이터프레임으로 만들기
df_OneHot = pd.DataFrame(encoder, columns=["class_" + str(oh.categories_[0][i]) for i in range (len(oh.categories_[0]))])
#원핫 인코딩 결과를 원본 데이터에 붙여넣기
df1 = pd.concat([df, df_OneHot], axis=1)
df1.head()
5.3 스케일링하기
5.3.1 정규화하기
# 원핫 인코딩 전 원본데이터 불러오기
df=df_origin.copy()
# 수치형 데이터만 분리하여 데이터프레임 만들기
df_num = df[['duration', 'days_left', 'price']]
# 정규화 수식적용하기
df_num = (df_num - df_num.min())/(df_num.max()-df_num.min())
df_num.head()
# 요약 데이터 확인해서 정규화 적용 확인하기
df_num.describe()
5.3.2 표준화하기
# 수치형 데이터만 분리하여 데이터프레임 만들기
df_num = df[['duration', 'days_left', 'price']]
# 표준화 수식 적용하기
df_num =(df_num - df_num .mean())/df_num .std()
df_num.head()
# 요약 데이터 확인해서 표준화 적용 확인하기
df_num.describe()
# 기존의 duration, days_left, price 칼럼 삭제하기
df=df.drop(['duration', 'days_left', 'price'], axis=1)
# 표준화된 duration, days_left, price 칼럼 붙이기
df = pd.concat([df, df_num], axis=1)
df.head()
5.4 변수 선택하기
5.4.1 신규 변수 생성하기
1. 하나의 데이터로 여러 개의 새로운 컬럼 만들기
# 항공기 기종을 제조사 코드와 모델명으로 분리하는 split_flight 함수 만들기
def split_flight(flight) :
# "-" 문자를 기준으로 앞쪽을 제조사 코드로 저장
manufacture = flight.split("-")[0]
# "-" 문자를 기준으로 뒤쪽을 모델명으로 저장
model = flight.split("-")[1]
# 제조사코드와 모델명을 리턴
return manufacture, model
# df['flight']를 split_flight함수의 파라미터로 넣어 실행하는 lambda, apply를 적용하여 제조사코드와 모델명 반환하기
# zip 함수를 사용하여 튜플로 묶어 df['manufacture'], df['model_num']에 저장하기
df['manufacture'], df['model_num']=zip(*df['flight'].apply(lambda x : split_flight(x)))
zip(*...): The * operator is used to unpack the list of tuples into two separate lists.
zip then takes these lists and pairs the corresponding elements together. Essentially,
it transposes the list of tuples.
2. 여러 개의 데이터로 하나의 새로운 컬럼 만들기
#source_city, destination_city를 튜블로 묶어 route 칼럼 생성하기
df['route']=df.apply(lambda x :(x['source_city'],x['destination_city']), axis=1)

- 이와 관련하여 RFE(Recursive Feature Elimination), RFE-CV(Recursive Feature Elimination with Cross Validation), UFS(Unvariate Feature Selection) 방법 등이 있음
6. Supervised Learning
6.1 머신러닝으로 지도학습
6.1.1 Linear Regression
1. 데이터 전처리
- 데이터 불러오기 → 데이터 pre-knowledge를 통한 Feature selection → 데이터 확인 후 Feature selection(모두 동일값, 모두 unique값 등등) → 결측치 처리 → 학습데이터/정답데이터 나누기(x,y) → train_test_split
- 원래는 스케일링도 해야함
# 판다스 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
df = pd.read_csv("../data/국민건강보험공단_건강검진정보_20211229.CSV", encoding='cp949')
# pandas display 옵션 조정을 통해 View 범위 확장하기
pd.set_option('display.max_columns', None) # display 옵션을 통한 전체 열 확장
# 가설을 참고하여 데이터 일부 삭제하기
# 시력, 청력, 치아 관련 칼럼은 관계없다는 가정으로 열 제거하기
df.drop(["치아우식증유무", '치석','시력(좌)', '시력(우)', '청력(좌)', '청력(우)',
'구강검진 수검여부'], axis=1, inplace=True)
# 기준년도 칼럼 확인하기 (모두 '2020' 동일 값이므로 '기준년도' 칼럼 삭제)
df.기준년도.value_counts()
# 가입자 일련번호 칼럼 확인하기 (모두 unique한 값으로 확인되어 '가입자 일련번호' 컬럼 삭제)
df["가입자 일련번호"].value_counts()
# 성별코드 칼럼 확인하기
df.성별코드.value_counts()
# 불필요한 데이터 삭제하기
df.drop(["기준년도", '가입자 일련번호', '데이터 공개일자', '성별코드', '시도코드'], axis=1, inplace=True)
# 별도의 test 데이터 추출하기
test = df[df['LDL 콜레스테롤'].isnull()] #나중에 예측치 구해서 기입할 수도 있으니까 in real practice
# NaN 데이터 행 단위로 삭제하기
train = df.dropna(axis=0)
# 정답 데이터 생성하기
y = train['LDL 콜레스테롤']
# 학습 데이터 생성하기
x = train.drop('LDL 콜레스테롤', axis=1)
# validation set 추출을 위한 train_test_split 라이브러리 불러오기
from sklearn.model_selection import train_test_split
# scikit learn 예시 코드 비율 대로 불러오기
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.33, random_state=42)
# 학습/검증 데이터 확인하기
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
2. 선형회귀 학습 및 추론하기
- 모델 생성하기 → 모델 학습하기 → 기울기와 절편 확인하기 #스케일링 했으면 회귀계수를 통해 무슨 특성이 주요 특성인지 확인 가능
# 라이브러리 불러오기
from sklearn.linear_model import LinearRegression
# 모델 생성하기
reg = LinearRegression()
# 학습하기
reg.fit(X_train,y_train)
# 기울기와 절편 확인하기
print(f'''기울기 및 절편 확인
기울기확인 coef = {reg.coef_}
절편확인 intercept = {reg.intercept_}''')
# 각각 데이터에 대해 가중치(or 회귀계수) 확인하기
print("전체에 대해서 가중치 확인")
for index ,columns in enumerate(X_train.columns):
print(f"{columns} = {reg.coef_[index]}")
3. 예측을 통한 최종 검증하기
- 예측하기 → evaluation metrics를 통한 모델 검증
# 예측하기
y_pred = reg.predict(X_test)
# 결과 검증을 위해 MSE 라이브러리 불러오기
# 최종적으로는 RMSE를 사용하기
from sklearn.metrics import mean_squared_error
# mse 라이브러리 에서 RMSE 는 squared 옵션을 False로 설정하기
rmse = mean_squared_error(y_test, y_pred, squared=False)
# rmse 확인하기
print(f'''rmse = {round(rmse,3)}''')
6.1.2 Logistic Regression
로지스틱 회귀 학습
#로지스틱 회귀 라이브러리 불러오기
from sklearn.linear_model import LogisticRegression
# 로지스틱 회귀 생성하기
logi_reg = LogisticRegression()
# 학습하기
logi_reg.fit(x_train, y_train)
# 역산을 위한 기울기와 절편이 있는지 확인하기
print('intercept:', logi_reg.intercept_)
print('coef:', logi_reg.coef_)
6.1.3 Decision tree
1. 데이터 준비하기
# 라이브러리 불러오기 (numpy, pandas, train_test_split)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# 데이터 불러오기
df = pd.read_csv("../data/국민건강보험공단_건강검진정보_20211229.CSV", encoding = 'cp949')
# 트리 예시를 만들기 위해서 일부 특성만 추출
sample_df = df[['신장(5Cm단위)','성별코드', '체중(5Kg 단위)','음주여부']]
2. 전처리하기
- 결측치 확인 및 처리 → 필요 컬럼 인코딩하기(생략됨) → 데이터 편향성 확인 → 학습/검증 데이터 분리
# info 정보로 결측치(Null) 확인하기
sample_df.info()
sample = sample_df.dropna()
# 결측치(Null) 다시 확인하기
sample.info()
# 원-핫 인코딩을 위해 데이터를 object 형태로 변경하기
sample = sample.astype('str')
# label(결과, Y) 생성하기
y=sample.음주여부
# 음주 여부 학습 데이터 구성하기
X=sample.drop('음주여부', axis=1)
# label 데이터의 편향성 확인하기
y.value_counts()
# 학습/검증 데이터 분리하기
x_train, x_valid, y_train, y_valid = train_test_split(
X, y,
test_size=0.2,
shuffle=True,
random_state=34
3. Decision tree 모델링
# 의사결정나무 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
# 의사결정나무 모델 생성하기
dt = DecisionTreeClassifier(random_state = 1001,
max_depth=2
)
# 의사결정나무 학습하기
dt_model = dt.fit(x_train, y_train)
# 학습 데이터 정확도 확인하기
print("학습 정확도 = ", dt_model.score(x_train, y_train))
# 검증 데이터 정확도 확인하기
print("검증 정확도 = ", dt_model.score(x_valid, y_valid))
4. 불순도 알아보기
# 불순도 함수 생성하기
def gini(x):
n = x.sum()
gini_sum = 0
for key in x.keys():
gini_sum = gini_sum + (x[key] / n ) * (x[key] / n )
gini = 1 - gini_sum
return gini
# 데이터 준비하기(불순도 예시)
과일바구니1 = ['사과']*9
과일바구니2 = ['사과', '바나나','사과', '바나나','바나나','바나나', '복숭아','복숭아','복숭아']
과일바구니3 = ['사과', '바나나','사과', '바나나','사과','복숭아', '복숭아','사과','복숭아']
print(round(gini(pd.DataFrame(과일바구니1).value_counts()),3))
print(round(gini(pd.DataFrame(과일바구니2).value_counts()),3))
print(round(gini(pd.DataFrame(과일바구니3).value_counts()),3))
6.1.4 Random Forest
1. 데이터 준비하기
- 3차원 행렬(이미지 데이터)는 2차원으로 변경해야함
# tensorflow에서 제공하는 데이터셋 mnist 불러오기
from tensorflow.keras.datasets.mnist import load_data
# load_data로 데이터 할당하기
(x_train, y_train), (x_test, y_test) = load_data()
# 손 글씨 데이터는 이미지라 3차원 행렬
print("변경 전 = ",x_train.shape)
변경 전 = (60000, 28, 28)
# 3차원 행렬을 2차원으로 변경하기
X_train = x_train.reshape(-1, 784)
X_test = x_test.reshape(-1, 784)
# 변경 결과 확인하기
print("변경 후 = ",X_train.shape)
2. Decision Tree와 Random Forest 모델링 및 비교
# 필요 라이브러리 불러오기(의사결정나무, 랜덤포레스트)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# 의사결정나무 학습하기
dct = DecisionTreeClassifier(random_state=0)
dct.fit(X_train, y_train)
# 의사결정나무 결과확인하기
acc_train_dct = dct.score(X_train,y_train)
acc_test_dct = dct.score(X_test,y_test)
print(f'''학습결과 = {acc_train_dct},검증결과 = {acc_test_dct} ''')
# 랜덤포레스트 학습하기
rfc = RandomForestClassifier(random_state=0)
rfc.fit(X_train, y_train)
# 랜덤포레스트 결과 보기
acc_train_rfc = rfc.score(X_train,y_train)
acc_test_rfc = rfc.score(X_test,y_test)
# 학습 결과 수치로 출력하기
print(f"""의사결정나무: train_acc = {round(acc_train_dct,3)}, test_acc = {round(acc_test_dct,3)}""")
print(f"""랜덤포레스트: train_acc = {round(acc_train_rfc,3)}, test_acc = {round(acc_test_rfc,3)}""")
# 랜덤포레스트 결과를 토대로 비교 그래프 그리기
import matplotlib.pyplot as plt
# x 축 정의하기
acc_list_x = ['dct_train', 'dct_test', 'rfc_train', 'rfc_test']
# y 축 정의
acc_list_y = [acc_train_dct, acc_test_dct, acc_train_rfc, acc_test_rfc]
# 막대그래프 차트 색 정의하기
colors = ['orange', 'orange' , 'blue', 'blue']
# 막대그래프 설정하기
plt.bar(acc_list_x, acc_list_y, color=colors)
# 화면 출력하기
plt.show()
6.1.5 Gradient Boosting
1. 데이터 준비하기
# tensorflow에서 데이터 불러오기
from tensorflow.keras.datasets.mnist import load_data
# 그래프 라이브러리 불러오기
import matplotlib.pyplot as plt
# 데이터 불러오기
(x_train, y_train), (x_test, y_test) = load_data()
# 학습시간 고려해서 2000건 데이터만 사용하기
x_train = x_train[:2000]
y_train = y_train[:2000]
x_test = x_test[:2000]
y_test = y_test[:2000]
# 샘플 데이터 확인하기
plt.imshow(x_train[7], cmap='Greys')
plt.show()

# 학습을 위한 2차원 행렬로 변경하기
X_train = x_train.reshape(-1, 784)
X_test = x_test.reshape(-1, 784)
2. 알고리즘 별 학습 및 결과 확인하기
# 의사결정나무, 랜덤포레스트, 그라디언트부스팅 라이브러리 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
# 의사결정나무 불러오기 및 학습하기
dct = DecisionTreeClassifier(random_state=0)
dct.fit(X_train, y_train)
# 의사결정나무 학습 결과 저장하기
acc_train_dct = dct.score(X_train,y_train)
acc_test_dct = dct.score(X_test,y_test)
# 랜덤포레스트 불러오기 및 학습하기
rfc = RandomForestClassifier(random_state=0)
rfc.fit(X_train, y_train)
# 랜덤포레스트 학습 결과 저장하기
acc_train_rfc = rfc.score(X_train,y_train)
acc_test_rfc = rfc.score(X_test,y_test)
# 그라디언트부스팅 불러오기 및 학습하기
gbc = GradientBoostingClassifier(random_state=0, verbose=1)
gbc.fit(X_train, y_train)
# 그라디언트부스팅 학습 결과 저장하기
acc_train_gbc = gbc.score(X_train,y_train)
acc_test_gbc = gbc.score(X_test,y_test)
# 각 알고리즘별 성능 비교하기
print(f"""의사결정나무: train_acc = {round(acc_train_dct,3)}, test_acc = {round(acc_test_dct,3)}""")
print(f"""랜덤포레스트: train_acc = {round(acc_train_rfc,3)}, test_acc = {round(acc_test_rfc,3)}""")
print(f"""그라디언트부스팅: train_acc = {round(acc_train_gbc,3)}, test_acc = {round(acc_test_gbc,3)}""")
# 비교 그래프 그리기
import matplotlib.pyplot as plt
acc_list_x = ['dct_train', 'dct_test', 'rfc_train', 'rfc_test', 'gbc_train', 'gbc_test', ]
acc_list_y = [acc_train_dct, acc_test_dct, acc_train_rfc, acc_test_rfc, acc_train_gbc, acc_test_gbc]
colors = ['orange', 'orange' , 'blue', 'blue', 'red', 'red']
plt.bar(acc_list_x,acc_list_y, color=colors)
plt.ylim([0.8,1.0])
plt.show()
6.2 딥러닝으로 지도학습
1. 데이터 파악
# csv 파일에서 데이터를 로드해서 데이터프레임으로 저장하기
df = pd.read_csv('../data/Invistico_Airline.csv')
# 데이터프레임 정보 확인하기
df.info()
# 데이터프레임의 처음 5개 행의 데이터 출력하기
df.head()
# 데이터프레임의 요약 통계량 확인하기
df.describe()
# 결측치 확인하기
df.isnull().sum()
2. 데이터 전처리
1. 결측치 처리
# SimpleImputer 객체로 결측치 대체하기
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder
mean_imputer = SimpleImputer(strategy='mean')
df["Arrival Delay in Minutes"] = mean_imputer.fit_transform(df[["Arrival Delay in Minutes"]])
2. 데이터 인코딩
# object 칼럼 유형을 string 유형으로 변경하기
cols = ['satisfaction', 'Gender', 'Customer Type', 'Type of Travel', 'Class']
df[cols] = df[cols].astype(str)
# 범주형 데이터를 수치값으로 변경하기
df['satisfaction'].replace(['dissatisfied','satisfied'], [0,1], inplace=True)
# 순서형 인코딩(Ordinal Encoding)하기
encoder = OrdinalEncoder(categories=[['Eco', 'Eco Plus', 'Business']])
df['Class'] = encoder.fit_transform(df[['Class']])
# 원핫 인코딩(One Hot Encoding)하기
cat_cols = ['Gender','Customer Type','Type of Travel']
df = pd.get_dummies(df, columns=cat_cols)
# 데이터 전처리 결과 확인하기
df.head()
# 데이터 유형 확인하기
df.dtypes
3. 데이터셋 분리하기
from sklearn.model_selection import train_test_split
# 데이터셋을 입력(X)과 레이블(y)로 분리하기
X = df.drop(['satisfaction'], axis=1)
y = df['satisfaction'].reset_index(drop=True)
# 데이터셋을 훈련 데이터와 검증 데이터로 분리하기
X_train, X_val, y_train, y_val = train_test_split(X, y,
test_size=0.2,
random_state=42,
stratify=y)
print(f'훈련 데이터셋 크기 : X_train {X_train.shape}, y_train {y_train.shape}')
print(f'검증 데이터셋 크기 : X_val {X_val.shape}, y_val {y_val.shape}')
4. 데이터 스케일링하기
from sklearn.preprocessing import MinMaxScaler
# 데이터 정규화하기
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_val = scaler.transform(X_val)
print(X_train)
5. 심층신경망 모델 생성 → 컴파일 → 학습
# 필요한 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Input, Dense, Dropout
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import random
# 모델 시드 고정하기
tf.random.set_seed(42)
np.random.seed(42)
random.seed(42)
# Keras의 Sequential 객체로 딥러닝 모델 구성하기
initializer = tf.keras.initializers.GlorotUniform(seed=42) #모델 시드 고정하기
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(25,),kernel_initializer=initializer))
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
# 모델을 학습시킬 최적화 방법, loss 계산 방법, 평가 방법 설정하기
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 학습하기
es = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1, restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100, batch_size=128,
verbose=1, validation_data=(X_val, y_val), callbacks=[es])- kernel_initializer를 지정하지 않아도 기본적으로 GlorotUniform 초기화 방법이 사용되므로 필요하지 않습니다. 하지만, 명시적으로 지정함으로써 코드의 명확성과 일관성을 높일 수 있습니다. 이는 특히 여러 초기화 방법을 실험하는 경우나 코드의 가독성을 높이고자 할 때 유용할 수 있습니다.
6. 훈련과정 시각화
import matplotlib.pyplot as plt
# 훈련 과정 정확도(accuracy) 시각화하기
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Validation'], loc='lower right')
plt.show()
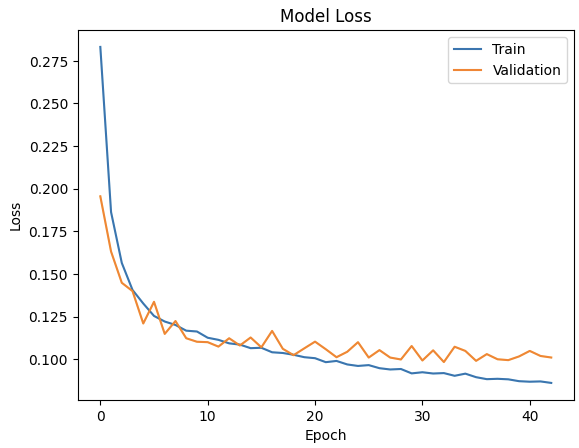
# 훈련 과정 손실(loss) 시각화하기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train', 'Validation'], loc='upper right')
plt.show()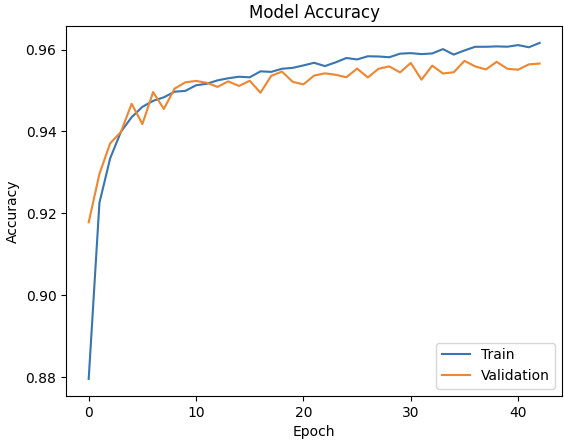
7. Unsupervised Learning
- 차원축소: 주성분 분석,t-분산
- 군집화:K-평균 군집화, DBSCAN
- 고객 세분화 모델 구현: RFM 분석, K-평균 군집화
7.1 차원축소
7.1.1 주성분 분석 in practice
1. 합성데이터 생성
# 라이브러리 불러오기
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 실습용 데이터셋 생성하기
x, y = make_blobs(n_features=10,
n_samples=1000,
centers=5,
random_state=2023,
cluster_std=1)
plt.scatter(x[:, 0], x[:, 1], c=y)
plt.show()
2. 데이터 표준화
# 라이브러리 불러오기
from sklearn.preprocessing import StandardScaler
# 데이터 표준화하기
scaler = StandardScaler()
scaler.fit(x)
std_data = scaler.transform(x)
print(std_data)
3. 주성분 분석
# 라이브러리 불러오기
import pandas as pd
from sklearn.decomposition import PCA
# PCA 객체로 주성분 10개 추출하기
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(std_data)
# 주성분 데이터 확인하기
pca_df = pd.DataFrame(reduced_data)
pca_df.head()# 설명된 분산(explained variance) 값 확인하기
print(pca.explained_variance_)
# 설명된 분산비율(explained variance ratio) 확인하기
print(pca.explained_variance_ratio_)
# 라이브러리 불러오기
import numpy as np
# 주성분의 설명력과 기여율 구하기
index = np.array([f'pca{n+1}' for n in range(reduced_data.shape[1])])
result = pd.DataFrame({'고유값' : pca.explained_variance_,
'기여율' : pca.explained_variance_ratio_},
index=index)
result['누적기여율'] = result['기여율'].cumsum()
# 주성분의 설명력과 기여율 확인하기
display(result)# PCA 객체로 주성분 4개 추출하기
pca = PCA(n_components=4)
X_reduced = pca.fit_transform(std_data)
print(pca.explained_variance_ratio_)
# 지정한 비율에 도달할 때까지 주성분을 탐색하기
pca = PCA(n_components=0.9)
reduced_data = pca.fit_transform(std_data)
print(pca.explained_variance_ratio_)
7.1.2 t-분산 확률적 이웃 임베딩 in practice
1. 합성데이터 생성
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 실습용 데이터셋 생성하기
x, y = make_blobs(n_features=10,
n_samples=100,
centers=3,
random_state=42,
cluster_std=2)
plt.scatter(x[:, 0], x[:, 1])
plt.show()
2. 2차원 t-SNE 시각화
import pandas as pd
from sklearn.manifold import TSNE
# 2차원 t-SNE 임베딩하기
tsne_np = TSNE(n_components = 2,random_state=1).fit_transform(x)
# Numpy array를 DataFrame으로 변환하기
tsne_df = pd.DataFrame(tsne_np, columns = ['component 0', 'component 1'])
print(tsne_df)
import matplotlib.pyplot as plt
# class target 정보 불러오기
tsne_df['target'] = y
# target별 분리하기
tsne_df_0 = tsne_df[tsne_df['target'] == 0]
tsne_df_1 = tsne_df[tsne_df['target'] == 1]
tsne_df_2 = tsne_df[tsne_df['target'] == 2]
# target별 시각화하기
plt.scatter(tsne_df_0['component 0'], tsne_df_0['component 1'],
color = 'pink', label = 'A')
plt.scatter(tsne_df_1['component 0'], tsne_df_1['component 1'],
color = 'purple', label = 'B')
plt.scatter(tsne_df_2['component 0'], tsne_df_2['component 1'],
color = 'yellow', label = 'C')
plt.xlabel('component 0')
plt.ylabel('component 1')
plt.legend()
plt.show()
3. 3차원 시각
# 3차원 t-SNE 임베딩하기
tsne_np = TSNE(n_components=3, random_state=15).fit_transform(x)
# Numpy array를 DataFrame으로 변환하기
tsne_df = pd.DataFrame(tsne_np,
columns = ['component 0', 'component 1', 'component 2'])
print(tsne_df)
from mpl_toolkits.mplot3d import Axes3D
# 3차원 그래프 세팅하기
fig = plt.figure(figsize=(9, 6))
ax = fig.add_subplot(111, projection='3d')
# class target 정보 불러오기
tsne_df['target'] = y
# target 별 분리하기
tsne_df_0 = tsne_df[tsne_df['target'] == 0]
tsne_df_1 = tsne_df[tsne_df['target'] == 1]
tsne_df_2 = tsne_df[tsne_df['target'] == 2]
# target 별 시각화하기
ax.scatter(tsne_df_0['component 0'],
tsne_df_0['component 1'],
tsne_df_0['component 2'],
color = 'pink', label = 'A')
ax.scatter(tsne_df_1['component 0'],
tsne_df_1['component 1'],
tsne_df_1['component 2'],
color = 'purple', label = 'B')
ax.scatter(tsne_df_2['component 0'],
tsne_df_2['component 1'],
tsne_df_2['component 2'],
color = 'yellow', label = 'C')
ax.set_xlabel('component 0')
ax.set_ylabel('component 1')
ax.set_zlabel('component 2')
ax.legend()
plt.show()
7.2 군집화
7.2.1 K-평균 군집화 in practice
# 라이브러리 불러오기
from sklearn.cluster import KMeans
import numpy as np
# 임의의 데이터 생성하기
X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]])
# K-평균 군집화 알고리즘 모델 생성하기
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# K-평균 군집화 알고리즘 결과 확인하기
print(kmeans.labels_)
print(kmeans.predict([[0, 0], [12, 3]]))
print(kmeans.cluster_centers_)
7.2.2 DBSCAN in practice
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# 실습용 데이터 생성하기
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(
n_samples=750, centers=centers, cluster_std=0.4, random_state=0
)
# 데이터 표준화하기
# fit_transform()은 fit()과 transform()을 합한 메소드임
X = StandardScaler().fit_transform(X)
# 데이터 시각화하기
plt.scatter(X[:, 0], X[:, 1])
plt.show()
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
# DBSCAN 모델 정의 및 학습하기
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
labels = db.labels_
# Noisy samples를 제외한 클러스터 개수 확인하기
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
# Noisy samples 개수 확인하기
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
# 평가 지표 출력하기
print(f"Homogeneity: {metrics.homogeneity_score(labels_true, labels):.3f}")
print(f"Completeness: {metrics.completeness_score(labels_true, labels):.3f}")
print(f"V-measure: {metrics.v_measure_score(labels_true, labels):.3f}")
print(f"Rand Index: {metrics.adjusted_rand_score(labels_true, labels):.3f}")
print(f"AMI: {metrics.adjusted_mutual_info_score(labels_true, labels):.3f}")
print(f"Silhouette Coefficient: {metrics.silhouette_score(X, labels):.3f}")
# 시각화하기
# 레이블 유일값 설정하기
unique_labels = set(labels)
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
# 클러스터 구분 색상 설정하기
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
# 시각화하기
for k, col in zip(unique_labels, colors):
if k == -1:
# 레이블이 -1로 지정된 Noise Point는 검은색으로 지정하기
col = [0, 0, 0, 1]
class_member_mask = labels == k
xy = X[class_member_mask & core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=14,
)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=6,
)
plt.title(f"Estimated number of clusters: {n_clusters_}")
plt.show()
7.3 고객 세분화 모델 구현
1. 데이터 로드 및 전처리 (Key point: 중복 데이터 제거 drop_duplicates)
# 필요한 라이브러리 불러오기
import datetime
import numpy as np
import datetime as dt
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 경고 메시지를 무시하도록 설정하기
import warnings
warnings.filterwarnings("ignore")
# 엑셀파일에서 데이터를 로드해서 데이터프레임으로 저장하기
df = pd.read_excel(
'https://archive.ics.uci.edu/ml/machine-learning-databases/00502/online_retail_II.xlsx',
engine="openpyxl")
# 데이터프레임의 처음 20개행의 데이터 출력하기
df.head(20)
# 데이터프레임의 요약 통계량 확인하기
df.describe()
# 결측치의 합계를 구해서 내림차순으로 정렬하기
df.isnull().sum().sort_values(ascending=False)
# 제품 수량과 가격이 0 이하인 데이터를 제거하기
df = df[(df['Quantity']>0) & (df['Price']>0)]
# 중복 데이터를 제거하기
df = df.drop_duplicates()
2. RFM 분석 기법을 이용한 고객 분류
# 최신성(Recency) 값을 계산하기 위해 마지막 날짜의 다음날을 계산하기
last_date = df.InvoiceDate.max() + datetime.timedelta(days=1)
# 구매수량과 제품가격을 곱하여 구매금액을 계산하기
df['Amount'] = df['Quantity'] * df['Price']
# groupby 함수로 고객별로 최근 구매 경과일, 구매건수, 구매금액 합계를 구하기
rfm = df.groupby('Customer ID').agg(
{'InvoiceDate': lambda InvoiceDate: (last_date - InvoiceDate.max()).days,
'Invoice': lambda Invoice: Invoice.nunique(),
'Amount': lambda Amount: Amount.sum()})
# 데이터프레임의 칼럼명 변경하기
rfm.columns = ['recency', 'frequency', 'monetary']
rfm.head()
3. 고객 점수 계산하기
# 최신성, 구매빈도, 구매금액을 1에서 5까지의 점수로 환산하기
rfm['recency_score'] = pd.qcut(rfm['recency'], 5,
labels=[5, 4, 3, 2, 1]).astype(int)
rfm['frequency_score'] = pd.qcut(rfm['frequency'].rank(method="first"), 5,
labels=[1, 2, 3, 4, 5]).astype(int)
rfm['monetary_score'] = pd.qcut(rfm['monetary'], 5,
labels=[1, 2, 3, 4, 5]).astype(int)
---------------------------------------------------------------------------------------------
# 최신성, 구매빈도, 구매금액의 환산점수 합계를 고객 점수(customer_score)로 저장하기
rfm['customer_score'] = rfm['recency_score'] + \
rfm['frequency_score'] + rfm['monetary_score']
# 데이터 확인하기
rfm.head(10)
---------------------------------------------------------------------------------------------
# 고객 점수(customer_score)가 만점(15점)인 고객 ID 확인하기
rfm[rfm['customer_score']==15].sort_values(
'monetary', ascending=False).head()
# 고객 등급 분류 함수 만들기
def level(score):
if score > 12 :
return 'VIP'
elif 9 < score <= 12:
return 'GOLD'
elif 5 < score <= 9 :
return 'SILVER'
else:
return 'WHITE'
# 고객 등급 분류 함수를 적용하여 고객 등급(level) 데이터 생성하기
rfm['level'] = rfm['customer_score'].apply(
lambda customer_score : level(customer_score))
rfm.head()
---------------------------------------------------------------------------------------------
# 고객 등급별 고객 수 그래프 출력하기
sns.countplot(x=rfm['level'])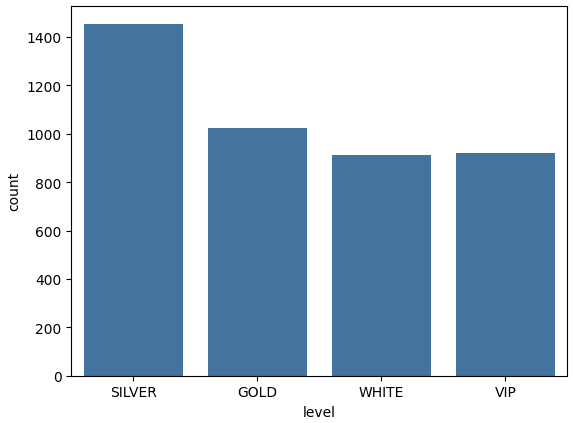
4. K-평균군집화 알고리즘을 이용한 고객 분류
# 데이터프레임의 요약 통계량 확인하기
rfm.describe()
---------------------------------------------------------------------------------------------
#이상치 제거 함수 작성하기
def processing_outlier(df, col_nm):
Q1 = df[col_nm].quantile(0.25)
Q3 = df[col_nm].quantile(0.75)
IQR = Q3 - Q1
df = df[(df[col_nm] >= Q1 - 1.5*IQR) & (df[col_nm] <= Q3 + 1.5*IQR)]
return df
# 비교를 위해 이상치 제거 전 데이터 저장하기
rfm_tmp = rfm.copy()
# recency 이상치 제거하기
rfm = processing_outlier(rfm, 'recency')
# 이상치 제거 전후 비교하기
fig = plt.figure(figsize=(14, 5)) # 그림 사이즈 지정 (가로 14인치, 세로 5인치)
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 이상치 제거 전 그래프 시각화
ax1.boxplot(rfm_tmp.recency)
# 이상치 제거 후 그래프 시각화
ax2.boxplot(rfm.recency)
---------------------------------------------------------------------------------------------
# frequency 이상치 제거하기
rfm = processing_outlier(rfm, 'frequency')
# 이상치 제거 전후 비교하기
fig = plt.figure(figsize=(14, 5)) # 그림 사이즈 지정 (가로 14인치, 세로 5인치)
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 이상치 제거 전 그래프 시각화
ax1.boxplot(rfm_tmp.frequency)
# 이상치 제거 후 그래프 시각화
ax2.boxplot(rfm.frequency)
# monetary 이상치 제거하기
rfm = processing_outlier(rfm, 'monetary')
# 이상치 제거 전후 비교하기
fig = plt.figure(figsize=(14, 5)) # 그림 사이즈 지정 (가로 14인치, 세로 5인치)
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
# 이상치 제거 전 그래프 시각화
ax1.boxplot(rfm_tmp.monetary)
# 이상치 제거 후 그래프 시각화
ax2.boxplot(rfm.monetary)
---------------------------------------------------------------------------------------------
rfm_k = rfm[['recency','frequency','monetary']]
# 데이터 표준화하기
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm_k)
print(rfm_scaled)
---------------------------------------------------------------------------------------------
# Elbow를 통한 최적의 n_clusters 파악
ks = range(1,11)
inertias=[]
for k in ks :
kc = KMeans(n_clusters=k,random_state=42)
kc.fit(rfm_scaled)
cluster = kc.fit_predict(rfm_scaled)
inertias.append(kc.inertia_)
# k vs inertia 그래프 그리기
plt.subplots(figsize=(10, 6))
plt.plot(ks, inertias, "bo-")
plt.xlabel("$k$", fontsize=14)
plt.ylabel('Inertia')
plt.annotate('Elbow',
xy=(3, inertias[2]),
xytext=(0.55, 0.55),
textcoords='figure fraction',
fontsize=16,
arrowprops=dict(facecolor='black', shrink=0.1)
)
plt.xticks(ks)
plt.style.use('ggplot')
plt.title('Best Number for KMeans')
plt.show()
---------------------------------------------------------------------------------------------
# K를 3으로 설정하고 군집 중심 찾기
kc = KMeans(3,random_state=42)
kc.fit(rfm_scaled)
identified_clusters = kc.fit_predict(rfm_k)
clusters_scaled = rfm_k.copy()
clusters_scaled['cluster_pred'] = kc.fit_predict(rfm_scaled)
print(f'Identified Clusters : {identified_clusters}')
print(f'Cluster Centers :\n{kc.cluster_centers_}')
# cluster_pred 칼럼의 값별로 count 하기
f, ax = plt.subplots(figsize=(25, 5))
ax = sns.countplot(x='cluster_pred', data=clusters_scaled)
# Pandas groupby 함수로 cluster_pred별 개수 집계하기
print(clusters_scaled.groupby(['cluster_pred']).count())
---------------------------------------------------------------------------------------------
rfm_k['cluster'] = clusters_scaled['cluster_pred']
rfm_k['level'] = rfm['level']
# recency, frequency, monetary의 평균값, 최솟값, 최댓값 구하기
rfm_k.groupby('cluster').agg({
'recency' : ['mean','min','max'],
'frequency' : ['mean','min','max'],
'monetary' : ['mean','min','max','count']
})